Everything fails eventually, even in networking. Enterprises can prepare for network failure by building resilience and redundancy into their network infrastructure design.
Resilience is defined as the ability to recover quickly from a setback or other adversity -- literally, the ability to spring back. So, with computer networks, how do we design resilience into the environment?
This article discusses four factors to consider when considering network resilience, as well as how enterprises can build redundancy into their network infrastructure.
1. Everything fails
The first step in designing a resilient network is to understand the reality that everything fails -- routers, switches, circuits, cables, small form-factor pluggables and even cross-connects. It's necessary to perform regular network maintenance. This maintenance keeps systems at appropriate software levels, permits the application of security patches and even provides for hardware maintenance and replacement.
2. Operating hours
Second, network teams need to think about the operating hours of the environment. For example, an office network may not have users after hours or on the weekends. This type of network might have strict reliability and availability requirements during regular hours, but it can be maintained after hours. Other environments, such as data centers or life and safety systems -- for example, 911 centers and hospitals -- need to run 24/7. As a result, a proper design for these networks needs to account for both failures and the ability to operate during maintenance.
The bottom line with resilience is enterprises need to apply redundancy at all layers of their infrastructure.
3. Virtualization, cloud and SaaS applications
The next step is to think about the effect of virtualization, cloud and SaaS application suites. While it might seem like cloud-based applications are outside IT's control, nothing could be further from the truth. For example, AWS makes significant effort to advise clients on the availability provided by applications. Applications provide substantially different service-level agreements to users depending on where they're hosted, such as in single availability zones, in multiple availability zones or operating across regions. It also matters how enterprises and their customers connect to cloud or SaaS providers.
4. Reliable remote connectivity
Finally, in the age of the COVID-19 pandemic, enterprises need to think about the reliability of their remote connectivity. Does the connectivity run on primary or secondary VPN concentrators, or is it load-balanced across a group of systems, permitting the necessary scale for maintenance?
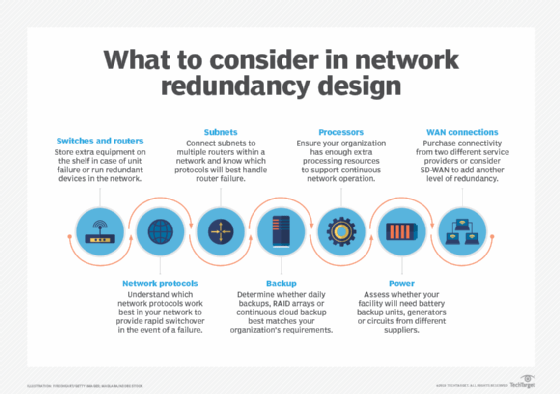
Consider these seven factors when building redundancy into your network.
Dozens of books are filled with advice on techniques to build resilient network design -- I recommend Computer Networking Problems and Solutions by Russ White and Ethan Banks. But the bottom line with resilience is enterprises need to apply redundancy at all layers of their infrastructure. This means designing with modularity and maintaining physical and logical separation between functional elements.
While site availability and resilience can be established with circuit and component redundancy, applications that require continuous availability need to be architected to be distributed over multiple data centers and availability zones. This permits operation of the application during AWS, VMware or other maintenance at any given location.
The most important component of this paradigm is the concept of network automation. This is how teams can ensure changes are not susceptible to human error. Scripting sets need vigorous review, and all changes require proper documentation and testing. Any given change requires a minimum set of scripts, which includes a script to enact the change and another to test and validate the change. Finally, teams need a plan to handle exceptions and have a backout script to return the environment to its pre-change baseline.