
animind - Fotolia
7 factors to consider in network redundancy design
Network pros should consider multiple factors when adding redundancy to network design, including network equipment, protocols, backup, processing and subnet connections.
Everything stops when the network goes down. For some enterprises, a few minutes of downtime isn't critical. For others, including those whose business depends on a customer-facing website, a few minutes of downtime means lost revenue and customers. It's critical for these enterprises to design a network that stays up despite a component failure.
Enterprises that are majorly affected by even a brief downtime must add redundant equipment and contract for redundant services. But adding network redundancy increases cost and complexity. Each organization should consider the tradeoff of downtime costs against the cost of adding devices and services.
Below are seven factors network teams should evaluate when building their network redundancy designs.
1. Switches and routers
Switches and routers are quite reliable, but they do sometimes fail. Some organizations find it sufficient to keep an extra switch or router on the shelf so they can quickly swap out a failing unit. Organizations with more critical needs must have redundant equipment up and running in the network.
2. Network protocols
Standards organizations have developed network protocols that provide rapid switchover to backup devices when a failure occurs. Adding redundancy at Layer 2 requires teams to connect more than a single switch to each subnet segment.
These additional switches create multiple paths through the network, resulting in network flooding with multiple copies of each packet. The Spanning Tree algorithm provides a way to determine a single path through the network. Unfortunately, Spanning Tree can take almost a minute to determine a new path. While this time frame might be acceptable for some networks, others require a more rapid recovery.
Newer protocols, including Multichassis Link Aggregation Group, or MLAG; Transparent Interconnection of Lots of Links, or TRILL; and Shortest Path Bridging, or SPB, have been developed to support faster recovery. Network teams that build network redundancy designs and require faster recovery must determine which option works best for their network.
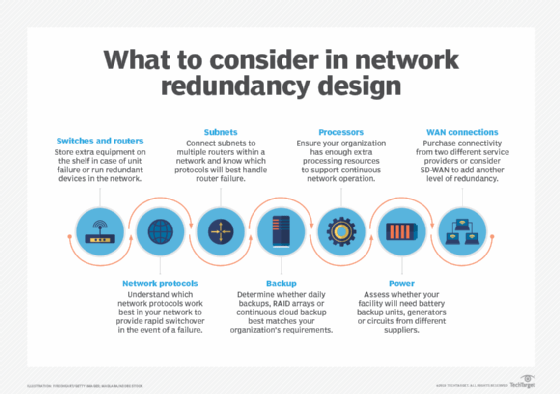
3. Subnet connections
The next step in adding redundancy is to connect subnets. Again, it's necessary to provide multiple paths between the subnets. Routers connect the subnets within a network and to external destinations. Each subnet must be connected to multiple routers to provide redundancy.
Protocols such as Open Shortest Path First (OSPF) and Enhanced Interior Gateway Routing Protocol (EIGRP) define how routers inform each other of the current optimum path to each destination.
Routers determine that a neighboring router is down when no updates arrive from that router for several seconds. However, both OSPF and EIGRP take more time to recover than some networks can accept. Hot Standby Router Protocol and Virtual Router Redundancy Protocol are available to reduce the amount of time needed to recover from a router failure.
A network connection can be disconnected for many reasons -- e.g., someone pulls the wrong wire, knocks a connection loose when adding a new connection or brushes against a cable while moving behind equipment. IEEE 802.3ad link aggregation defines how to use two cables for a single connection. Traffic can be shared across the two cables as long as both are connected, but it continues to flow when one is disconnected.
4. Backup
A disk failure that results in loss of data can impede business operations. Some organizations are fine with a daily backup, while others can't accept the loss of one day's data and the time required to recover.
RAID protects against the failure of a single disk, and it offers multiple levels of protection. Each item of data can be written on two different disks. Higher protection levels define ways to add additional disks and parity information. This capability enables teams to recover correct data in case two disks that should contain identical data differ.
Continuous cloud backup has advantages over the highest RAID levels because sending each data update to the cloud means no data is lost. Individual RAID disks are installed in a single cabinet, which means damage to that cabinet can wipe out all the individual disks. Meanwhile, it's still necessary to periodically back up the array, but data accumulated after the most recent backup is still lost.
5. Processors
Processors can fail just like other components, so it's important to consider them in network redundancy designs. In addition to the possibility of failure, processors must be regularly updated with the latest system software release. It's necessary for organizations to have enough extra processing resources to guarantee continuous network operation.
Moving all processing and storage to a public cloud can simplify the task of designing in redundancy. Clouds have many processors and storage units, applications can quickly move to another processor in the event of failure and redundant storage can be configured. If some event shuts down an entire facility, processing can move to a distant location.
6. Power
Nothing works without power, which can fail because of a storm, a pole knocked down by a car or any number of other reasons. Battery backup can take over quickly in the event of a failure, but this option can require a large number of backup units for large facilities.
Switching to a generator takes more time, but it can pick up the load if the blackout lasts beyond battery capacity. In some cases, it's also possible to connect to two different supplier circuits to survive wire damage along one of the supplier's routes.
7. WAN and SD-WAN
WAN connections have always been important, but the growth of cloud computing and the importance of remote users have made WAN reliability increasingly critical.
One option for enterprises is to procure connections to two different network service providers. While this adds expense, it protects against failure along the link to the provider and failure within the provider's network.
Software-defined WAN (SD-WAN) provides an additional way to add network redundancy. MPLS circuits are quite reliable and guarantee a specified level of quality of service (QoS), but they can fail. An SD-WAN controller can switch traffic to the internet in the event of failure. The public internet doesn't provide the same level of reliability or QoS guarantees, but it provides a way to get data to its destination.
Another advantage of SD-WAN is it can move less-critical traffic to the internet during times of maximum load, rather than driving teams to contract for the maximum level of MPLS bandwidth required during the year.
Consider redundancy in network design
Adding redundancy increases expense and complexity. Designers shouldn't design more network redundancy than is necessary. But they also can't design less redundancy than required, as even a short disruption can mean enterprise success or failure.
Editor's note: This article was updated to improve the reader experience.







