software-defined networking (SDN)
What is software-defined networking?
Software-defined networking (SDN) is an architecture that abstracts different, distinguishable layers of a network to make networks agile and flexible. The goal of SDN is to improve network control by enabling enterprises and service providers to respond quickly to changing business requirements.
In a software-defined network, a network engineer or administrator can shape traffic from a centralized control console without having to touch individual switches in the network. A centralized SDN controller directs the switches to deliver network services wherever they're needed, regardless of the specific connections between a server and devices.
This process is a move away from traditional network architecture, in which individual network devices make traffic decisions based on their configured routing tables. SDN has played a role in networking for a decade now and has influenced many innovations in networking.
SDN architecture
A typical representation of SDN architecture comprises three layers: the application layer, the control layer and the infrastructure layer. These layers communicate using northbound and southbound application programming interfaces (APIs).
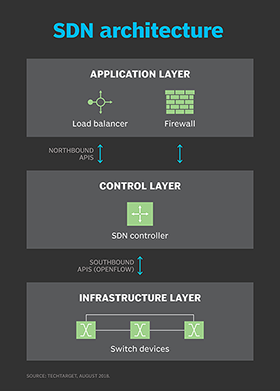
Application layer
The application layer contains the typical network applications or functions organizations use. This can include intrusion detection systems, load balancing or firewalls. Where a traditional network would use a specialized appliance, such as a firewall or load balancer, a software-defined network replaces the appliance with an application that uses a controller to manage data plane behavior.
Control layer
The control layer represents the centralized SDN controller software that acts as the brain of the software-defined network. This controller resides on a server and manages policies and traffic flows throughout the network.
Infrastructure layer
The infrastructure layer is made up of the physical switches in the network. These switches forward the network traffic to their destinations.
APIs
These three layers communicate using respective northbound and southbound APIs. Applications talk to the controller through its northbound interface. The controller and switches communicate using southbound interfaces, such as OpenFlow, although other protocols exist.
There is currently no formal standard for the controller's northbound API to match OpenFlow as a general southbound interface. It is likely the OpenDaylight controller's northbound API may emerge as a de facto standard over time, given its broad vendor support.
How does SDN work?
SDN encompasses several types of technologies, including functional separation, network virtualization and automation through programmability.
Originally, SDN technology focused solely on the separation of the network control plane from the data plane. While the control plane makes decisions about how packets should flow through the network, the data plane moves packets from place to place.
In a classic SDN scenario, a packet arrives at a network switch. Rules built into the switch's proprietary firmware tell the switch where to forward the packet. These packet-handling rules are sent to the switch from the centralized controller.
The switch -- also known as a data plane device -- queries the controller for guidance as needed and provides the controller with information about the traffic it handles. The switch sends every packet going to the same destination along the same path and treats all the packets the same way.
Software-defined networking uses an operation mode that is sometimes called adaptive or dynamic, in which a switch issues a route request to a controller for a packet that does not have a specific route. This process is separate from adaptive routing, which issues route requests through routers and algorithms based on the network topology, not through a controller.
The virtualization aspect of SDN comes into play through a virtual overlay, which is a logically separate network on top of the physical network. Users can implement end-to-end overlays to abstract the underlying network and segment network traffic. This microsegmentation is especially useful for service providers and operators with multi-tenant cloud environments and cloud services, as they can provision a separate virtual network with specific policies for each tenant.
What are the benefits of SDN?
SDN can come with a variety of benefits, such as the following.
Simplified policy changes
With SDN, an administrator can change any network switch's rules when necessary -- prioritizing, deprioritizing or even blocking specific types of packets with a granular level of control and security.
This capability is especially helpful in a cloud computing multi-tenant architecture, as it enables the administrator to manage traffic loads in a flexible and efficient manner. Essentially, this enables administrators to use less expensive commodity switches and have more control over network traffic flows.
Network management and visibility
Other benefits of SDN are network management and end-to-end visibility. A network administrator needs to deal with only one centralized controller to distribute policies to the connected switches. This is opposed to configuring multiple individual devices.
This capability is also a security advantage because the controller can monitor traffic and deploy security policies. If the controller deems traffic suspicious, for example, it can reroute or drop the packets.
Reduced hardware footprint and Opex
SDN also virtualizes hardware and services that were previously carried out by dedicated hardware. This results in the touted benefits of a reduced hardware footprint and lower operational costs.
Networking innovations
SDN also contributed to the emergence of software-defined wide area network (SD-WAN) technology. SD-WAN employs the virtual overlay aspect of SDN technology. SD-WAN abstracts an organization's connectivity links throughout its WAN, creating a virtual network that can use whichever connection the controller deems fit to send traffic.
What are the challenges of SDN?
Main adopters of SDN include service providers, network operators, telecoms, carriers and large companies, such as Facebook and Google. However, there are still some challenges behind SDN.
Security
Security is both a benefit and a concern with SDN technology. The centralized SDN controller presents a single point of failure and, if targeted by an attacker, can prove detrimental to the network.
Unclear definition
Another challenge with SDN is the industry really has no established definition of software-defined networking. Different vendors offer various approaches to SDN, ranging from hardware-centric models and virtualization platforms to hyper-converged networking designs and controllerless methods.
Market confusion
Some networking initiatives are often mistaken for SDN, including white box networking, network disaggregation, network automation and programmable networking. While SDN can benefit and work with these technologies and processes, it remains a separate technology.
Slow adoption and costs
SDN technology emerged with a lot of hype around 2011 when it was introduced alongside the OpenFlow protocol. Since then, adoption has been relatively slow, especially among enterprises that have smaller networks and fewer resources. Many enterprises cite the cost of SDN deployment to be a deterring factor.
SDN use cases
Some use cases for SDN include the following:
- DevOps.SDN can facilitate DevOps by automating application updates and deployments. This strategy can include automating IT infrastructure components as the DevOps apps and platforms are deployed.
- Campus networks.Campus networks can be difficult to manage, especially with the ongoing need to unify Wi-Fi and Ethernet networks. SDN controllers can benefit campus networks by offering centralized management and automation, improved security and application-level quality of service across the network.
- Service provider networks. SDN helps service providers simplify and automate the provisioning of their networks for end-to-end network and service management and control.
- Data center security. SDN supports more targeted protection and simplifies firewall administration. Generally, enterprises depend on traditional perimeter firewalls to secure their data centers. However, companies can create a distributed firewall system by adding virtual firewalls to protect the virtual machines. This extra layer of firewall security helps prevent a breach in one virtual machine from jumping to another. SDN centralized control and automation also enables admins to view, modify and control network activity to reduce the risk of a breach.
The impact of SDN
Software-defined networking has had a major effect on the management of IT infrastructure and network design. As SDN technology matures, it not only changes network infrastructure design but also how IT views its role.
SDN architectures can make network control programmable, often using open protocols, such as OpenFlow. Because of this, enterprises can apply aware software control at the edges of their networks. This enables access to network switches and routers, rather than using the closed and proprietary firmware generally used to configure, manage, secure and optimize network resources.
While SDN deployments are found in every industry, the effect of the technology is strongest in technology-related fields and financial services.
SDN is influencing the way telecommunications companies operate. For example, Verizon uses SDN to combine all its existing service edge routers for Ethernet and IP-based services into one platform. The goal is to simplify the edge architecture, enabling Verizon to enhance operational efficiency and flexibility to support new functions and services.
SDN's success in the financial services sector hinges on connecting to large numbers of trading participants, low latency and a highly secure network infrastructure to power financial markets worldwide.
Nearly all the participants in the financial market depend on legacy networks that can be non-predictive, hard to manage, slow to deliver and vulnerable to attacks. With SDN technology, organizations in the financial services sector can build predictive networks to enable more efficient and effective platforms for financial trading apps.
SDN and SD-WAN
SD-WAN is a technology that distributes network traffic across WANs using SDN concepts to automatically determine the most effective way to route traffic to and from branch offices and data center sites.
SDN and SD-WAN share similarities. For example, they both separate the control plane and data plane, and they both support the implementation of additional virtual network functions.
However, while SDN primarily focuses on the internal operations within a local area network, SD-WAN focuses on connecting an organization's different geographical locations. This is done by routing applications to the WAN.
Other differences between SDN and SD-WAN include the following:
- Customers can program SDN, while the vendor programs SD-WAN.
- SDN is enabled by network functions virtualization (NFV) within a closed system. SD-WAN, on the other hand, offers application routing that runs virtually or on an SD-WAN appliance.
- SD-WAN uses an app-based routing system on consumer-grade broadband internet. This enables better quality performance and a lower cost per megabyte than Multiprotocol Label Switching (MPLS), which is critical to SDN.
SDN and SD-WAN are two different technologies aimed at accomplishing different business goals. Typically, small and midsize businesses use SDN in their centralized locations, while larger companies that want to establish interconnection between their headquarters and off-premises sites use SD-WAN.







