Fog computing architecture posing challenges for IT
Fog computing architecture designs are gaining traction, as users demand accessibility to apps and services. But the approach can cause challenges for IT.
As the processing power of always-on devices continues to accelerate and network bandwidth ramps up, the notion of fog computing is gaining traction.
Fog computing architecture calls for as much of the processing as possible to be pushed out of large-scale data centers in favor of individual devices at the edge. How does it work? Consider, if you will, the process of tagging images of people uploaded to a social media site.
In the old days, also known as Before Cloud, the user would download or install a piece of software from floppy disks -- remember those? -- and run this software across a database of images. He would manually tag some number of images, which would then teach the software which face belonged to which person. The software would become more accurate over time, eventually being able to classify images based on faces and other content. The user would still need to correct the occasional image, of course, but the longer the software was used -- and the more images it was used against -- the more accurate it would become.
Post-Cloud, the world ran a little differently. Now, users would purchase a service that can classify images, or tag people in the images they upload. This service might not be paid for with actual money, but might be paid for in privacy, as is the case with most large-scale social media services. In this model, the user takes a picture, uploads it, and the image is processed in a large-scale data center located at some distance from the user -- the cloud. Once processing is completed, the image is loaded to the social media service with the appropriate tags. Of course, users can still correct the tagging, allowing the service to learn faces and situations more accurately over time.
Why fog computing architecture designs are helpful
There are two main reasons facial recognition works better on the cloud than on personal devices. The first is there is more information available. Training a neural network -- or some other learning algorithm -- to recognize a person's face is greatly improved by the addition of more data. The more faces you can have classified, with more users doing the classification, the more accurate the software becomes. Access to a large data set is, therefore, a major help in building such services.
The second is there is more processing power available. It is impossible for a single handheld device to compete with the power available in a large data center, anchored by hundreds of thousands -- or millions -- of compute cores and lots of drive space.
Fog computing architecture takes an alternative tack. First, even a large-scale data center with lots of access to compute power cannot compete with the millions of devices sitting in user's hands. Second, higher-speed networks make it possible to potentially move enough information around to make processes like tagging images possible on smaller, local devices.
This is particularly true if the software can draw on data sets available in nearby devices, such as the tags other users have placed on images taken in the same location. For instance, if you and I both take a picture of the same building, the contents of my image can be narrowed down quickly by looking at what tag you put on your copy of the image.
Conveniently, the geographic location of items in the image corresponds to the geographic location of the user creating the image, as well as the geographic location of other users creating similar images. These facts can help narrow the range of possibilities, making the problem of recognizing faces and objects much more tractable within the confines of the processing and computing power locally available.
Adopting the framework of fog computing -- and some challenges
These two considerations -- the economic model of fog and the interaction between fog computing and the shape of the internet -- illustrate why it is often important to consider the entire network as a system.
Some companies are already capitalizing on this kind of fog computing architecture; for instance, in the January 2018 edition of The Communications of the ACM, published by the Association of Computing Machinery, Jacob Loveless wrote about his experience in building a distributed caching system based loosely on network connectivity, which somewhat correlates to geographic location. In this paper, he described building software that will load static content from devices around the local device, significantly reducing load time -- sometimes by 50%.
This basic idea of fog computing is extremely attractive, primarily for this one advantage: page load times. Page load times can be directly correlated to how long users are engaged, whether they are satisfied and how they might interact with advertising messages. This is similar to brick-and-mortar stores, which arrange the physical aisles to keep shoppers in the store as long as possible. Furthermore, the more time on site users spend, the more information they tend to give up, and the more they tend to interact with other users. Both drive up the value of the social media site.
There are, however, two significant obstacles facing fog computing architecture. The first is the most obvious: Who pays for the user's resources? To draw information from a nearby device, that device must expend electrical power, compute power, memory and bandwidth. Each of these resources costs some amount of money. Should a user who pays for more resources see those resources go toward providing faster page load speeds for those around her, ultimately to the economic benefit of a content provider? If not, how will these uses be paid for?
If you think net neutrality is a tangled mess, wait until users and providers start wading into these waters. The most likely result will be users just ignore this problem, because they are receiving faster page loads. But the value extracted from the user is likely to be larger than the value the user is receiving.
A second, not-so-obvious problem lurks just behind.
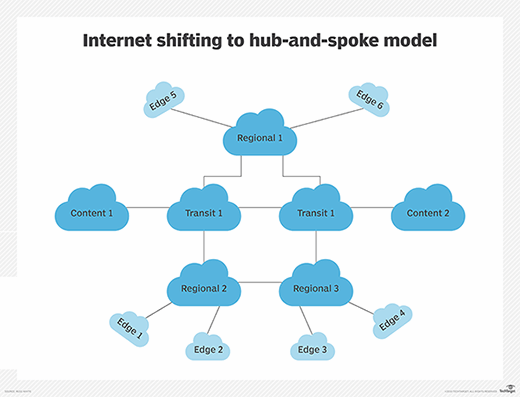
The fog computing architecture model assumes the internet will remain pretty much as it is, with strong mesh-like interconnections close to the edge. Is this model sustainable in a world dominated by a small number of destinations? Geoff Huston, in a post at APNIC, noted that, according to traffic and connectivity patterns, the internet appears to be moving from a strongly interconnected network to a more hub-and-spoke design, as illustrated below.
A hub-and-spoke model can cause bottlenecks
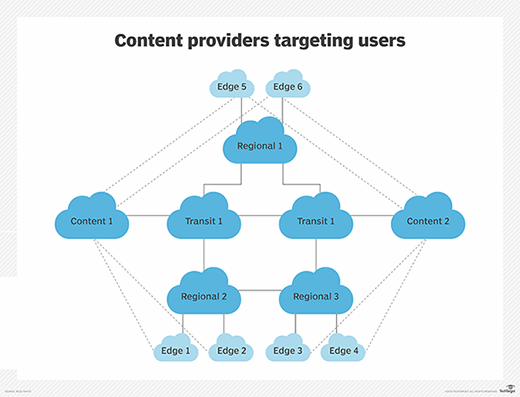
In this network approach, the content providers must pass through transit providers, and then through regional providers and, finally, through edge providers to reach their users. Each hop in this network costs money and time, however -- both of which undercut the operation of the content providers. What is now happening, according to Huston, is content providers are going directly to their users, as shown below.
Direct connections can weaken ties between providers in disparate geographic regions
In this network, the content providers have built out a larger network, directly connecting to edge networks. Typically, such connections are not physical connections to the edge networks, as shown, but rather connections to local internet exchange points, which provide a direct connection between the content provider and several edge network providers, as well as edge-connected operators -- what might typically be called enterprise networks. One effect of these direct connections is the connections between providers not located in the same geographic region become weaker.
These weakening ties may, over time, create a challenge for a more open fog computing model. Fog computing could become a way for content providers to offload the work of running a social media network onto their users, while providing little benefit in the way of new or innovative services. This pattern of connectivity is one of the subtler issues companies staking their future on fog computing need to understand and consider.
These two considerations -- the economic model of fog and the interaction between fog computing and the shape of the internet -- illustrate why it is often important to consider the entire network as a system. The sooner network engineers can break out of narrowly focusing on solving a single problem, replacing their vendor-driven, product-oriented thinking with a larger view, the sooner network they will find themselves in the position of managing a strategic -- rather than commodity -- infrastructure.